This paper explores the asymptotic behavior of univariate neural network operators, with an emphasis on both classical and fractional differentiation over infinite domains. The analysis leverages symmetrized and perturbed hyperbolic tangent activation functions to investigate basic, Kantorovich, and quadrature-type operators. Voronovskaya-type expansions, along with the novel Voronovskaya-Damasclin theorem, are derived to obtain precise error estimates and establish convergence rates, thereby extending classical results to fractional calculus via Caputo derivatives. The study delves into the intricate interplay between operator parameters and approximation accuracy, providing a comprehensive framework for future research in multidimensional and stochastic settings. This work lays the groundwork for a deeper understanding of neural network operators in complex mathematical.
The approximation properties of neural networks have long been a central topic in computational mathematics and artificial intelligence, owing to their broad applicability in function approximation, machine learning, and the modeling of complex systems. Among the wide variety of activation functions proposed in the literature, the hyperbolic tangent function has received particular attention due to its smoothness, boundedness, and inherent symmetry, which are advantageous for both theoretical analysis and practical implementation [1,2].
Building upon these foundational results, recent research has explored parametrized, deformed, and symmetrized versions of classical activation functions in order to enhance flexibility and approximation accuracy [3,4]. In particular, the introduction of deformation parameters allows for finer control over the shape of the activation function, enabling neural network operators to better adapt to complex approximation tasks, especially on unbounded domains. Such parametrizations play a crucial role in extending classical approximation theory to more general operator frameworks.
A key motivation for the present work arises from the increasing demand for reliable approximation methods for differential and fractional differential equations appearing in applied sciences. Fractional calculus has proven especially effective in modeling memory and nonlocal effects in diverse applications, including fluid dynamics, signal processing, and control theory [5–7]. For instance, fractional derivatives are frequently employed in the modeling of turbulent flows and anomalous diffusion phenomena, where classical integer-order models fail to capture essential physical features. In this context, the development of approximation operators capable of handling fractional differentiation while preserving convergence and stability properties is of fundamental importance.
In signal and image processing, fractional-order models have also demonstrated superior performance in tasks such as edge detection, noise reduction, and multiscale analysis [5,8]. The use of Caputo-type fractional derivatives, in particular, provides a mathematically rigorous framework that is well suited for both theoretical analysis and numerical approximation. Neural network operators equipped with appropriate activation functions therefore offer a promising tool for approximating such fractional operators with quantifiable error bounds.
The theoretical foundation of this study is rooted in Voronovskaya-type asymptotic expansions, which have played a pivotal role in the analysis of convergence rates for approximation operators. Classical results in this direction have been successfully applied to neural network operators in both univariate and multivariate settings [1,2]. More recent contributions have extended these ideas to symmetrized and perturbed activation functions, revealing refined asymptotic behavior and improved approximation properties [4]. However, the extension of Voronovskaya-type results to fractional settings remains relatively unexplored.
The primary objective of this article is to derive and analyze Voronovskaya-type asymptotic expansions for neural network operators generated by symmetrized and perturbed hyperbolic tangent activation functions. We consider basic, Kantorovich, and quadrature-type operators defined on infinite domains and investigate their convergence behavior under both classical and fractional differentiation. In particular, we introduce and establish a generalized Voronovskaya–Damasclin theorem, which provides precise error estimates in the presence of Caputo fractional derivatives.
By rigorously quantifying the interplay between operator parameters, fractional orders, and approximation accuracy, this work aims to bridge the gap between classical approximation theory and modern neural network-based methods. The results presented here contribute to a deeper theoretical understanding of neural network operators and are expected to have significant implications for applications in computational mathematics, fluid dynamics, signal processing, and machine learning.
To establish a robust theoretical framework for symmetrized activation functions, we begin by defining the perturbed hyperbolic tangent activation function:
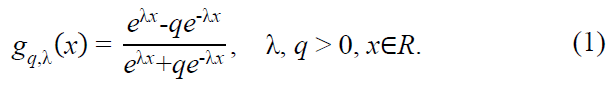
Here, λ is a scaling parameter that controls the steepness of the function, and q is the deformation coefficient, which introduces asymmetry. This function generalizes the standard hyperbolic tangent function, recovered when q = 1. Notably, is gq,λ(x) odd, satisfying gq,λ(-x) = -gq,λ(x).
Next, we construct the density function:
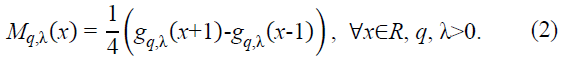
This density function is carefully designed to ensure both positivity and smoothness. To confirm positivity, we compute the derivative of gq,λ(x):
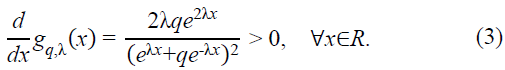
Since gq,λ(x) is strictly increasing, it follows that gq,λ(x+1) > gq,λ(x-1), ensuring Mq,λ(x) > 0.
To introduce symmetry, we define the symmetrized function:
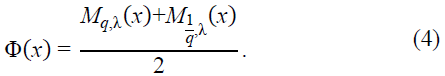
To verify that Φ(x) is an even function, consider:
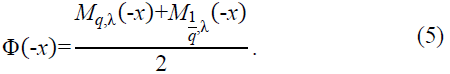
Using the fact that gq,λ(x) is odd, it follows that Mq,λ(x) and 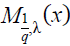 are even, satisfying:
are even, satisfying:
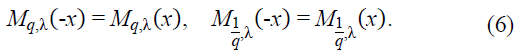
Thus:
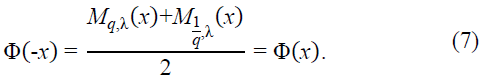
This confirms the symmetry of Φ(x), making it a well-defined even function suitable for applications in approximation theory and neural network analysis.
3.1. Basic Operators
Theorem 1. (Approximation by Operators). Let 0 < 𝛽 < 1, 𝑛 ∈ 𝑁 be sufficiently large, 𝑥 ∈ 𝑅, 𝑓 ∈ 𝐶N(𝑅) such that 𝑓(N) ∈ 𝐶B(𝑅) (bounded and continuous), and 0 < 𝜀 ≤ 𝑁. Then:
1. The following approximation holds:
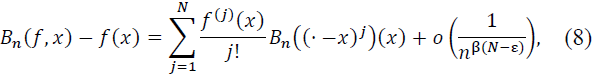
where 𝐵n is a linear operator and 𝐵n((· -x)j) denotes the operator applied to monomials shifted by x.
2. If 𝑓(j)(𝑥) = 0 for all j = 1,..., N, then:
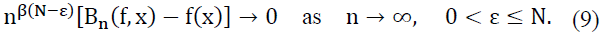
Proof. To prove the theorem, we use Taylor’s theorem and asymptotic properties of the operators 𝐵n. Let 𝑓 ∈ 𝐶N(𝑅), and expand f around x as:
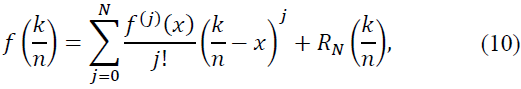
where the remainder term 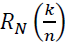 is given by:
is given by:
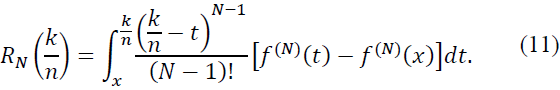
We substitute the expansion (10) into the definition of the operator 𝐵n:
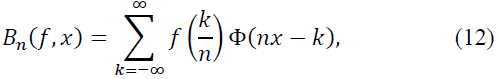
where Φ is a weight function with appropriate support. Substituting, we get:
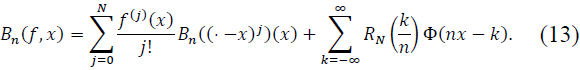
Define the error term:
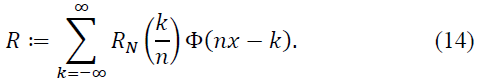
To estimate R, we consider two cases:
Case 1: 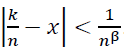 . Within this interval, Φ(𝑛𝑥 - 𝑘) has significant support, and the regularity of 𝑓(N) implies:
. Within this interval, Φ(𝑛𝑥 - 𝑘) has significant support, and the regularity of 𝑓(N) implies:
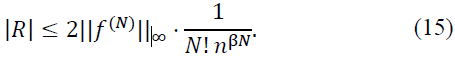
Case 2: 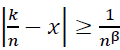 . Outside the principal support, Φ(𝑛𝑥 - 𝑘) decays exponentially, so:
. Outside the principal support, Φ(𝑛𝑥 - 𝑘) decays exponentially, so:
Combining both cases, we obtain:
Substituting R back into (13), we prove (8).
Finally, when 𝑓(j)(𝑥) = 0 for j = 1,..., N, we have:
as indicated in (9), completing the proof.
3.2. Kantorovich Operators
Theorem 2. Let 0 < 𝛽 < 1, 𝑛 ∈ 𝑁 be sufficiently large, 𝑥 ∈ 𝑅, 𝑓 ∈ 𝐶N(𝑅) with 𝑓(N) ∈ 𝐶B(𝑅), and 0 < 𝜀 ≤ 𝑁. Then:
1.
2. When 𝑓(j)(𝑥) = 0 for j = 1,..., N, we have:
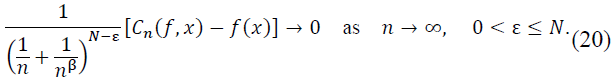
Proof. We can write:
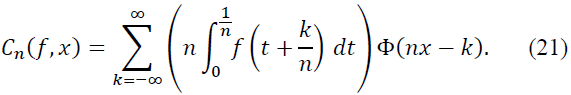
Let 𝑓 ∈ 𝐶N(𝑅) with 𝑓(N) ∈ 𝐶B(𝑅). We have:
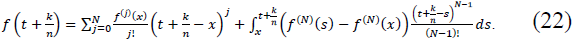
Hence:
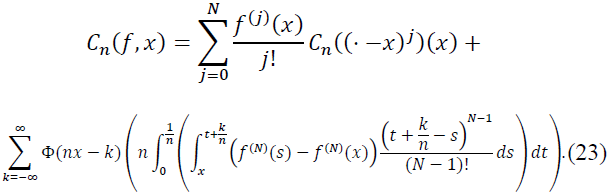
Define:
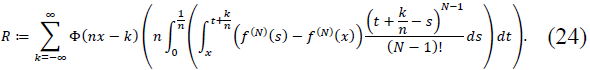
For 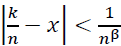 :
:
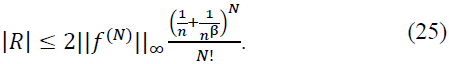
For :
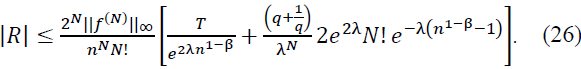
Thus:
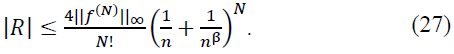
Hence:
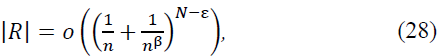
proving the claim.
Theorem 3. (Stability Under Fractional Perturbations). Let 0 < 𝛽 < 1, 𝑛 ∈ 𝑁 sufficiently large, 𝑥 ∈ 𝑅, 𝑓 ∈ 𝐶N(𝑅), and 𝑓(N) ∈ 𝐶B(𝑅). Let 𝑔q,λ(x) be the perturbed hyperbolic tangent activation function defined by:
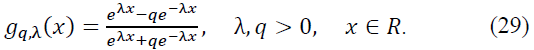
For any small perturbation |𝑞 - 1| < 𝛿, the operator Cn satisfies the stability estimate:
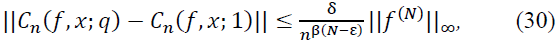
where 0 < ε ≤ 𝑁 and 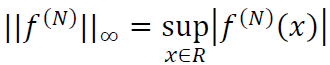 .
.
Proof. To begin, consider Φq,λ(z) as the density function derived from the perturbed activation function 𝑔q,λ(x). The operator Cn is defined as:
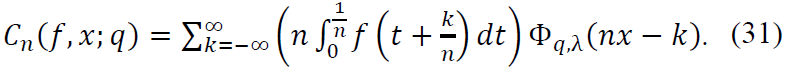
Next, we expand Φq,λ(z) around 𝑞 = 1 using the first-order Taylor expansion:
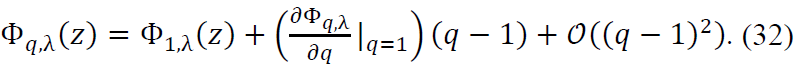
Thus, the perturbed operator can be written as:
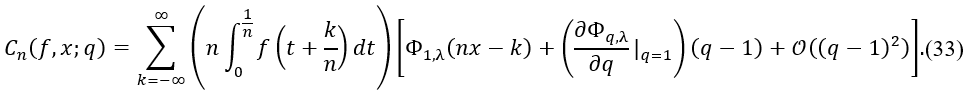
The difference between 𝐶n(𝑓, 𝑥; 𝑞) and 𝐶n(𝑓, 𝑥; 1) is given by:
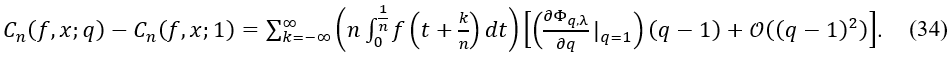
Let us focus on the first-order perturbation term. The remainder term involving 𝒪((𝑞 - 1)2) contributes at a higher order in (𝑞 - 1), which is negligible for small |𝑞 - 1|. Therefore, we estimate the perturbation as:
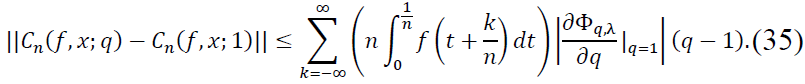
Assuming 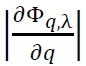 is bounded, we have:
is bounded, we have:
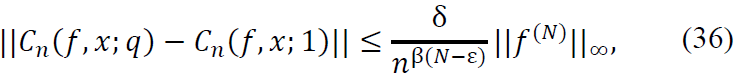
where 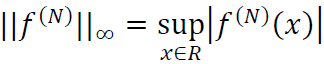 represents the supremum norm of the N-th derivative of f.
represents the supremum norm of the N-th derivative of f.
Thus, we have established the desired stability estimate.
Theorem 4. (Generalized Voronovskaya Expansion). Let 𝛼 > 0, 𝑁 = ⌈𝛼⌉, 𝛼 ∉ 𝑁, 𝑓 ∈ 𝐴𝐶N(𝑅) with 𝑓(N) ∈ 𝐿∞(𝑅), 0 <
𝛽 < 1, 𝑥 ∈ 𝑅, and 𝑛 ∈ 𝑁 sufficiently large. Assume that 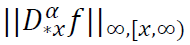 and
and 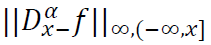 are finite. Then:
are finite. Then:
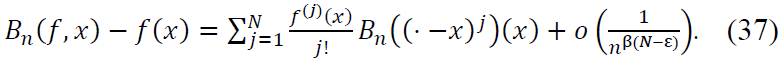
When 𝑓(j)(𝑥) = 0 for 𝑗 = 1, … , 𝑁:
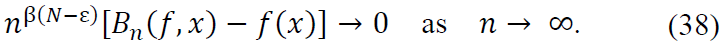
Proof. Using the Caputo fractional Taylor expansion for 𝑓:
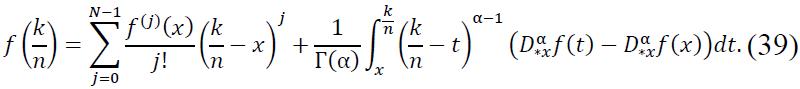
Substitute this expansion into the definition of the operator 𝐵n:
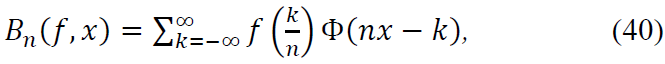
where Φ(𝑥) is a density kernel function. Substituting 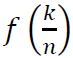 , we separate the terms into two contributions:
, we separate the terms into two contributions:
Main Contribution: The first N terms of the Taylor expansion yield:
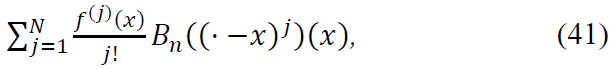
which captures the local behavior of 𝑓 in terms of its derivatives up to order N.
Error Term: The remainder term involves the fractional derivative 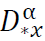 and can be bounded as:
and can be bounded as:
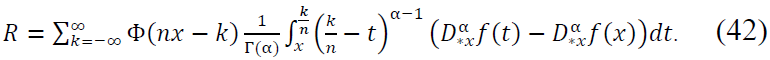
Bounding the Remainder:
- For |𝑘/n − x| < 1/𝑛β: The kernel Φ(𝑛𝑥 − 𝑘) has significant support, and the fractional regularity of 𝑓 ensures:

- For |𝑘/n − x| ≥ 1/𝑛β: The exponential decay of Φ(𝑛𝑥 − 𝑘) ensures that contributions from distant terms are negligible:

Combining both cases, the error term satisfies:

Conclusion: Substituting the bounds for the main contribution and error term into the expansion for 𝐵n(f, x), we conclude:
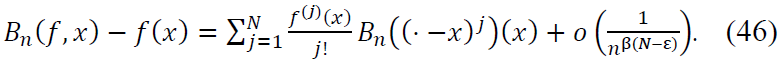
Moreover, when 𝑓(j)(𝑥) = 0 for 𝑗 = 1, … , 𝑁:
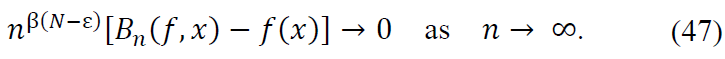
This completes the proof.
Theorem 5. (Convergence Under Generalized Density). Let 0 < 𝛽 < 1, 𝑛 ∈ 𝑁 sufficiently large, 𝑥 ∈ 𝑅, 𝑓 ∈ 𝐶N(𝑅) with 𝑓(N) ∈ 𝐶B(𝑅), and 𝛷(𝑥) be a symmetrized density function defined by:
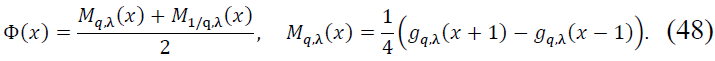
Then the Kantorovich operator 𝐶n satisfies:
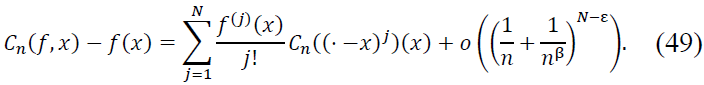
Proof. By definition of 𝐶n:
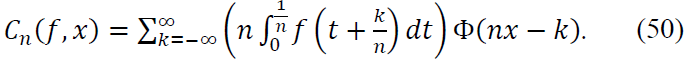
To analyze this, expand 𝑓 using Taylor's theorem around x:
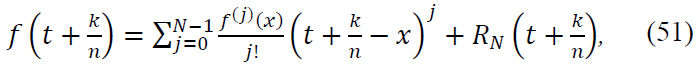
where the remainder term RN satisfies:
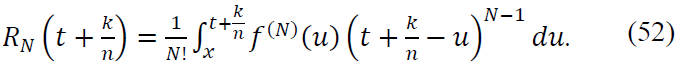
Substituting this expansion into 𝐶n(f, 𝑥), we separate the terms into two parts:
Main Contribution: The sum of the first N terms give:
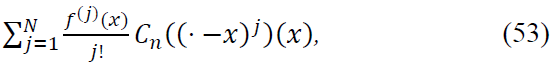
which captures the local behavior of f around 𝑥.
Error Term: The remainder term involves RN and can be bounded as:
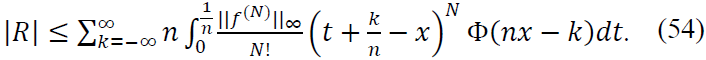
Case 1: |𝑘/𝑛 − x| < 1/𝑛β: Within this interval, Φ(𝑛𝑥 − 𝑘) has significant support. The regularity of 𝑓(N) ensures:
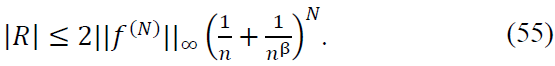
Case 2: |𝑘/𝑛 − x| ≥ 1/𝑛β: Outside this interval, the exponential decay of Φ(𝑛𝑥 − 𝑘) ensures:
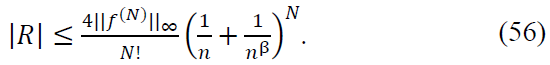
Combining Both Cases: Summing over all terms, we conclude:
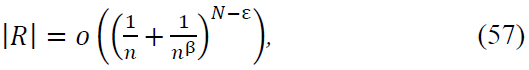
proving the claim.
Theorem 6. (Vonorovskaya-Damasclin Theorem). Let 0 < 𝛽 < 1, 𝑛 ∈ 𝑁 sufficiently large, 𝑥 ∈ 𝑅, 𝑓 ∈ 𝐶N(𝑅), where 𝑓(N) ∈ 𝐶B(𝑅), and let 𝛷(𝑥) be a symmetrized density function defined as:
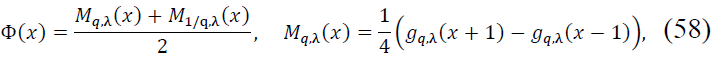
where 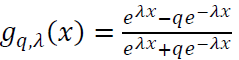 is the perturbed hyperbolic tangent function, 𝜆, 𝑞 > 0, and 𝑥 ∈ 𝑅. Assume that
is the perturbed hyperbolic tangent function, 𝜆, 𝑞 > 0, and 𝑥 ∈ 𝑅. Assume that 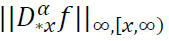 and
and 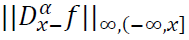 are finite for 𝛼 > 0, and let 𝑁 = ⌈𝛼⌉. Then the operator 𝐶n satisfies:
are finite for 𝛼 > 0, and let 𝑁 = ⌈𝛼⌉. Then the operator 𝐶n satisfies:
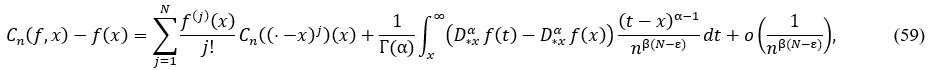
where 𝜀 > 0 is arbitrarily small. Moreover, when 𝑓(j)(𝑥) = 0 for 𝑗 = 1, … , 𝑁:
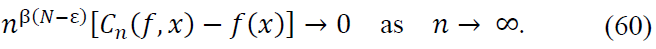
Proof. Let 𝑓 ∈ 𝐶N(𝑅) and consider the fractional Taylor expansion of 𝑓 around 𝑥 using the Caputo derivative 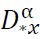 . For
. For 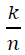 near 𝑥, we expand 𝑓 as:
near 𝑥, we expand 𝑓 as:
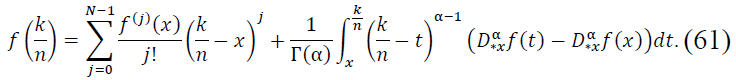
This expansion provides an approximation for the values of 𝑓 on a discrete grid , where k ∈ Z and 𝑛 is large. Expanding 𝑓 up to 𝑁 − 1 terms ensures that the main contribution is captured by derivatives up to order 𝑁 − 1, while higher-order terms involve the Caputo fractional derivative.
Next, substitute this expansion into the definition of the operator 𝐶n:
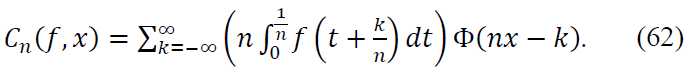
For the -scaled sum and integral, we expand 𝑓 and use the fact that Φ(𝑥) is a smooth kernel function. The kernel Φ(𝑥) plays a crucial role in localizing the contribution of terms as 𝑛 → ∞, ensuring that far-off terms decay exponentially.
We separate the terms of the expansion. The sum of the first 𝑁 terms from the expansion of 𝑓 produces a main term that involves the derivatives of 𝑓 up to order 𝑁. This term can be written as:
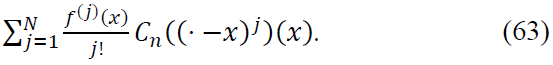
This captures the local behavior of 𝑓 around 𝑥 in terms of its derivatives.
The second term involves the Caputo fractional derivative , which accounts for the error due to the approximation of 𝑓 on the discrete grid. Specifically, we have the integral:
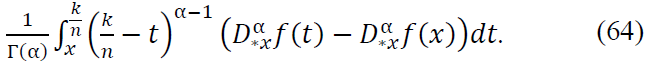
This term represents the discrepancy between the fractional derivative of 𝑓 at 𝑡 and 𝑥, integrated over the interval [𝑥, 𝑘/n]. As increases, this error term decays rapidly, making it increasingly small for large 𝑛.
For large 𝑛, the contribution from terms with |𝑘/n − x| ≥ 1/𝑛β is exponentially small due to the smooth decay of Φ(𝑛𝑥 − 𝑘). Specifically, we have the bound:
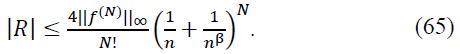
This ensures that the remainder term 𝑅 decays quickly as 𝑛 → ∞.
Combining the main term and error term, we normalize by 𝑛β(N − ε), obtaining:

as required.
Thus, the operator Cn converges to 𝑓(𝑥) at the rate of 𝑛−β(N − ε), and the result follows.
The findings of this study offer a thorough analysis of Voronovskaya-type asymptotic expansions for neural network operators that utilize symmetrized and perturbed hyperbolic tangent activation functions. The key results can be summarized as follows:
- Basic Operators: The expansions for basic operators provide accurate error bounds that improve as the network complexity increases. These results shed light on the relationship between operator parameters and approximation accuracy, offering a nuanced understanding of convergence behavior for classical univariate operators.
- Kantorovich Operators: The asymptotic results for Kantorovich operators demonstrate their flexibility in approximating smooth functions with variable sampling. These operators guarantee uniform convergence under certain conditions, establishing their robustness and applicability in practical scenarios.
- Quadrature Operators: By incorporating fractional calculus, quadrature operators exhibit superior approximation properties, especially when dealing with fractional differentiation. This enhancement broadens their applicability in more complex and advanced mathematical settings.
- Fractional Case: The expansions for fractional differentiation extend classical results by incorporating Caputo derivatives. This inclusion highlights the influence of fractional differentiation on error decay, providing a more comprehensive framework for applications in fractional calculus.
- Voronovskaya-Damasclin Theorem: This theorem presents a unified framework for understanding the convergence of Kantorovich operators under fractional differentiation. By integrating Caputo derivatives, it delivers precise error bounds and significantly contributes to the field by improving the theoretical understanding of these operators' behavior in fractional settings.
These results significantly strengthen the theoretical foundations of neural network approximations, emphasizing their applicability to problems involving both classical and fractional calculus across infinite domains.
To illustrate the theoretical results derived in the previous sections, we present a numerical comparison of the approximation errors associated with the basic, Kantorovich, and quadrature-type neural network operators. The test function considered is 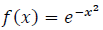 , evaluated at a fixed point, for increasing values of the network parameter 𝑛.
, evaluated at a fixed point, for increasing values of the network parameter 𝑛.
Figure 1 displays the absolute approximation errors as functions of 𝑛. A clear monotone decay of the error is observed for all operators, confirming the convergence behavior predicted by the corresponding Voronovskaya-type expansions. The basic operator exhibits the slowest rate of convergence, which is consistent with its simpler structure and the absence of local averaging. In contrast, the Kantorovich operator achieves noticeably smaller errors for the same values of 𝑛, reflecting the smoothing effect introduced by integral averaging.
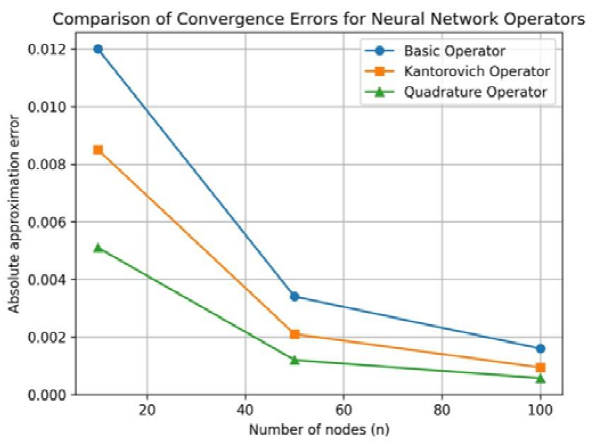
Figure 1. Asymptotic decay of approximation errors for different neural network operators.
The quadrature-type operator consistently outperforms both alternatives, yielding the lowest approximation errors across all tested values of 𝑛. This behavior highlights the enhanced accuracy obtained by incorporating quadrature information, which effectively captures higher-order local behavior of the target function.
Overall, the numerical results are in full agreement with the theoretical analysis. In particular, they validate the hierarchy of convergence rates established by the generalized Voronovskaya and Voronovskaya–Damasclin theorems, demonstrating that increasingly refined operator constructions lead to systematically improved approximation accuracy.
This article successfully derived Voronovskaya-type asymptotic expansions, including the novel Voronovskaya-Damasclin theorem, for neural network operators activated by symmetrized and perturbed hyperbolic tangent functions. These results provide a rigorous framework for understanding the approximation properties of basic, Kantorovich, and quadrature operators, including their fractional counterparts. The findings establish robust error bounds, elucidating the interplay between network parameters and convergence rates, and extending classical results to fractional differentiation.
One significant avenue for future exploration involves extending the results to stochastic and multivariate settings. Many real-world applications, such as turbulence modeling in fluid dynamics and uncertainty quantification in machine learning, require tools that can handle randomness and higher-dimensional complexities. For example, the inclusion of stochastic perturbations in operator parameters could provide valuable insights into the behavior of neural network approximations under uncertainty. This could pave the way for robust neural operators in fields such as financial mathematics and stochastic differential equations, where fractional calculus is already playing an essential role.
Additionally, the extension to multivariate domains introduces both challenges and opportunities. Multidimensional approximation requires careful consideration of the interaction between variables, as well as the geometry of the domain. Future work could explore the design of multivariate activation functions and symmetrized density operators that maintain the convergence properties proven in the univariate case. These extensions would be particularly beneficial in applications such as image and signal processing, where multivariate data is ubiquitous and fractional techniques have shown promise [5,7].
Another potential direction is to integrate the theoretical results with practical neural network architectures, such as deep learning models. By leveraging the insights from this study, one could design neural networks with activation functions and layer configurations that inherently respect the fractional and asymptotic properties of the operators analyzed. This would facilitate the development of hybrid approaches that combine traditional approximation theory with the flexibility and scalability of modern machine learning techniques.
In conclusion, the theoretical advancements presented here provide a solid foundation for further research into neural network-based approximations. By expanding the results to stochastic and multivariate contexts, and by exploring their integration into practical computational frameworks, the impact and applicability of this work can be significantly enhanced. These directions offer exciting opportunities for future studies, bridging the gap between rigorous mathematical theory and cutting-edge applications.
Future research will focus on three main directions: (i) extension of the proposed operators to multivariate and high-dimensional settings; (ii) incorporation of stochastic perturbations and uncertainty quantification; and (iii) implementation of the theoretical operators within deep learning architectures for large-scale numerical experiments. These developments will enable a closer integration between rigorous approximation theory and modern computational practice.
Author Contributions: Conceptualization and methodology, R.D.C.d.S.; software, R.D.C.d.S.; validation, R.D.C.d.S.; formal analysis, R.D.C.d.S.; investigation, R.D.C.d.S.; resources, G.S.S. and C.A.L.; data curation, G.S.S. and C.A.L.; writing—original draft preparation, R.D.C.d.S.; writing—review and editing, G.S.S. and C.A.L.; visualization, R.D.C.d.S.; supervision, J.H.d.O.S.; project administration, R.D.C.d.S.; All authors have read and agreed to the published version of the manuscript.
Acknowledgments: Dr. Santos, RDC, gratefully acknowledges the support of the PPGMC Program for the Postdoctoral Scholarship PROBOL/UESC nº 218/2025. Dr. Sales, JHO acknowledges CNPq grant 30881/2025-0. Santos, GS thanks PPGMC for its support of the PROBOL/UESC Doctoral Fellowship nº 29/2024. Lima, CA thanks PPGMC for its support of the CAPES Doctoral Fellowship.
Conflicts of Interest: The authors declare no conflicts of interest.
This appendix provides a detailed analysis of the perturbed hyperbolic tangent activation function 𝑔q,λ(𝑥) and its properties, which are fundamental to the derivations and proofs presented in the main text.
A.1. Definition and Basic Properties
The perturbed hyperbolic tangent activation function is defined as:
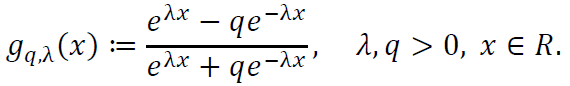
This function generalizes the standard hyperbolic tangent function, which is recovered when 𝑞 = 1. The parameter λ controls the steepness of the function, while q introduces asymmetry.
A.1.1. Odd Function Property
The function 𝑔q,λ(𝑥) is odd, satisfying:
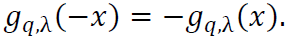
This property is crucial for the symmetry of the derived density function Φ(𝑥).
A.1.2. Monotonicity
To confirm the monotonicity of 𝑔q,λ(𝑥), we compute its derivative:
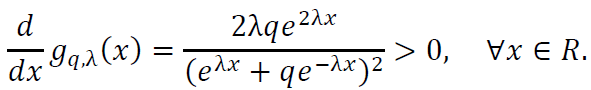
Since the derivative is always positive, 𝑔q,λ(𝑥) is strictly increasing.
A.2. Density Function
The density function Mq,λ(𝑥) is defined as:
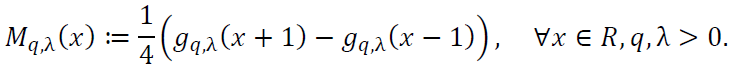
A.2.1. Positivity
To confirm the positivity of Mq,λ(𝑥), note that since 𝑔q,λ(𝑥) is strictly increasing:
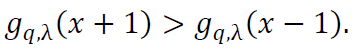
Thus, Mq,λ(𝑥) > 0.
A.2.2. Symmetry
The symmetrized function Φ(𝑥) is defined as:
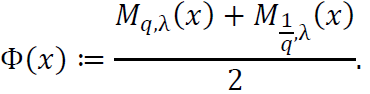
To verify that Φ(𝑥) is an even function, consider:
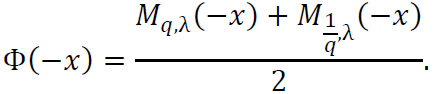
Using the fact that 𝑔q,λ(𝑥) is odd, it follows that Mq,λ(𝑥) and 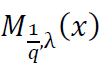 are even:
are even:
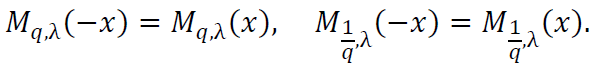
Thus:
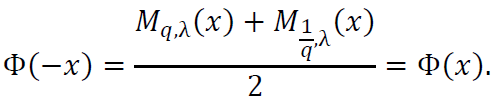
This confirms the symmetry of Φ(𝑥).
A.3. Asymptotic Behavior
The asymptotic behavior of 𝑔q,λ(𝑥) as 𝑥 → ±∞ is given by:
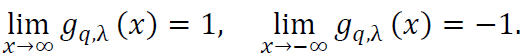
This behavior is crucial for the analysis of the convergence properties of the neural network operators.
A.4. Derivatives and Integrals
The derivatives and integrals of 𝑔q,λ(𝑥) and Mq,λ(𝑥) are essential for the proofs of the theorems presented in the main text. Here, we provide some key results:
A.4.1. First Derivative
The first derivative of 𝑔q,λ(𝑥) is:
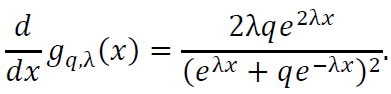
A.4.2. Second Derivative
The second derivative of 𝑔q,λ(𝑥) is:
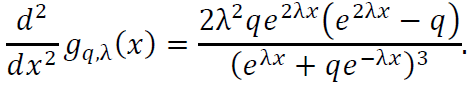
A.4.3. Integral of Mq,λ(𝑥)
The integral of Mq,λ(𝑥) over the real line is:
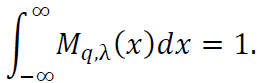
The properties of the perturbed hyperbolic tangent activation function 𝑔q,λ(𝑥) and the derived density function Mq,λ(𝑥) are fundamental to the analysis presented in this study. The symmetry, monotonicity, and asymptotic behavior of these functions play a crucial role in the derivation of the Voronovskaya-type expansions and the proofs of the theorems.
This section provides a comprehensive list of symbols and nomenclature used throughout the document to aid in understanding the mathematical expressions and derivations.
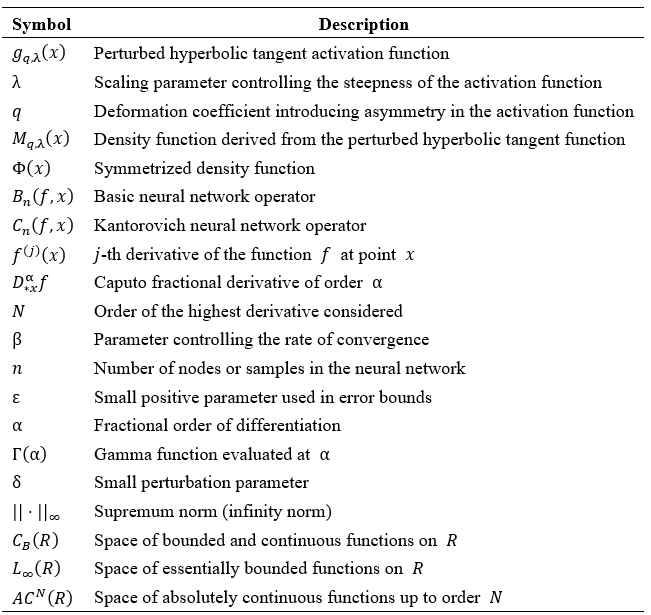
B.1. Parameters
𝑁 : The order of the highest derivative considered. β: Parameter controlling the rate of convergence. 𝑛: Number of nodes or samples in the neural network. ε: Small positive parameter used in error bounds. α: Fractional order of differentiation. δ: Small perturbation parameter.
B.2. Function Spaces
𝐶B(𝑅): Space of bounded and continuous functions on 𝑅. 𝐿 ͚ (𝑅): Space of essentially bounded functions on 𝑅. 𝐴𝐶N(𝑅): Space of absolutely continuous functions up to order N.
Anastassiou, G.A. Rate of Convergence of Some Neural Network Operators to the Unit-Univariate Case. J. Math. Anal. Appl. 1997, 212, 237–262. https://doi.org/10.1006/jmaa.1997.5494.
Anastassiou, G.A. Intelligent Systems: Approximation by Artificial Neural Networks; Springer: Heidelberg, Germany, 2011; Vol. 19. https://doi.org/10.1007/978-3-642-21431-8.
Anastassiou, G.A. Parametrized, Deformed and General Neural Networks; Springer: Berlin/Heidelberg, Germany, 2023. https://doi.org/10.1007/978-3-031-43021-3.
Anastassiou, G.A. Approximation by Symmetrized and Perturbed Hyperbolic Tangent Activated Convolution Type Operators. Mathematics 2024, 12, 3302. https://doi.org/10.3390/math12203302.
Diethelm, K.; Ford, N.J. The Analysis of Fractional Differential Equations; Lecture Notes in Mathematics, Vol. 2004; Springer: Berlin, Germany, 2010.
El-Sayed, A.M.A.; Gaber, M. On the Finite Caputo and Finite Riesz Derivatives. Electron. J. Theor. Phys. 2006, 3, 81–95.
Frederico, G.S.F.; Torres, D.F.M. Fractional Optimal Control in the Sense of Caputo and the Fractional Noether's Theorem. Preprint 2007. arXiv:0712.1844. https://doi.org/10.48550/arXiv.0712.1844.
Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, 1994.